Oregon Landslide Data Preprocessing#
Overview#
This notebook processes landslide data from Oregon’s Statewide Landslide Information Database for Oregon (SLIDO) into a standardized format for integration with other regional datasets.
The workflow includes:
Data Loading: Load GeoDataFrame layers from SLIDO database
Deposits Analysis: Examine the main deposits layer structure and data quality
References Processing: Load and integrate citation references from the References layer. Merge reference information with landslide records using REF_ID_COD
Data Standardization: Standardize confidence levels, movement types, and material classifications
Column Selection: Select and rename columns to match unified schema
Quality Assurance: Validate data completeness and geometry integrity
Export: Save processed data as GeoJSON for further analysis
Key Data Layers:
Deposits: Landslide records with detailed attributes
References: 376 citation records linked via REF_ID_COD
Obtain the State Statewide Landslide Information Database for Oregon (SLIDO) from the official DOGAMI website: https://www.oregon.gov/dogami/slido/Pages/data.aspx
Create a directory ‘Data’ in your projects root folder and place the downloaded files inside it.
Initialization#
import fiona
import geopandas as gpd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
gdb_dir = "../data/Oregon/SLIDO_Release_4p5_wMetadata.gdb"
layers = fiona.listlayers(gdb_dir)
print("Available layers in the GDB:")
for lyr in layers:
df = gpd.read_file(gdb_dir, layer=lyr)
print(f"{lyr:35s} {len(df):6d} data points")
Available layers in the GDB:
Index_LS_Studies 72 data points
C:\Users\loicb\anaconda3\envs\landslide\Lib\site-packages\pyogrio\raw.py:198: RuntimeWarning: organizePolygons() received a polygon with more than 100 parts. The processing may be really slow. You can skip the processing by setting METHOD=SKIP, or only make it analyze counter-clock wise parts by setting METHOD=ONLY_CCW if you can assume that the outline of holes is counter-clock wise defined
return ogr_read(
Detailed_Deep_Landslide_Susceptibility 4 data points
References 376 data points
Detailed_Susceptibility_Map_Index 12 data points
Historic_Landslide_Points 15386 data points
Scarp_Flanks 28650 data points
Scarps 55824 data points
Deposits 71318 data points
Inventory_Map_Index 1569 data points
Inventory_Map_Index_2 355 data points
Inventory_Map_Index_3 355 data points
References_Check_In_Map_Index_3 21 data points
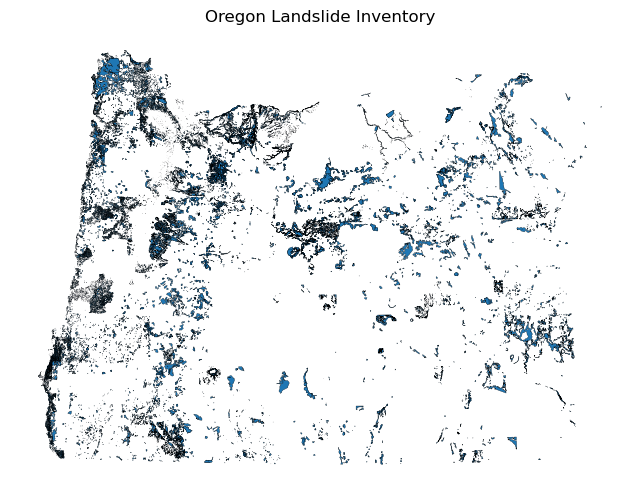
deposits = gpd.read_file(gdb_dir, layer="Deposits")
deposits.plot(figsize=(8, 6), edgecolor="k", linewidth=0.2)
plt.title("Oregon Landslide Inventory")
plt.axis("off")
plt.show()
Initial Inspection#
deposits = gpd.read_file(gdb_dir, layer="Deposits")
print("Total number of deposits:", len(deposits))
Total number of deposits: 71318
print(deposits.shape)
print(deposits.dtypes)
(71318, 33)
UNIQUE_ID object
TYPE_MOVE object
MOVE_CLASS object
MOVE_CODE object
CONFIDENCE object
AGE object
DATE_MOVE object
NAME object
GEOL object
SLOPE float32
HS_HEIGHT float32
FAN_HEIGHT float32
FAIL_DEPTH float32
DEEP_SHAL object
HS_IS1 float32
IS1_IS2 float32
IS2_IS3 float32
IS3_IS4 float32
HD_AVE float32
DIRECT float32
AREA float32
VOL float32
REF_ID_COD object
MAP_UNIT_L object
DESCRIPTION object
YEAR float64
DATE_RANGE object
REACTIVATION object
MONTH object
DAY object
Shape_Length float64
Shape_Area float64
geometry geometry
dtype: object
import pandas as pd
def completeness(df: pd.DataFrame):
total = len(df)
comp = df.count() # non-null counts per column
pct = (comp / total * 100).round(1)
return pd.DataFrame({"non_null": comp, "% filled": pct})
df_completeness = completeness(deposits)
df_completeness.sort_values(by='% filled', ascending=False)
| non_null | % filled | |
|---|---|---|
| UNIQUE_ID | 71318 | 100.0 |
| REF_ID_COD | 71318 | 100.0 |
| Shape_Area | 71318 | 100.0 |
| Shape_Length | 71318 | 100.0 |
| DESCRIPTION | 71318 | 100.0 |
| geometry | 71318 | 100.0 |
| AREA | 61271 | 85.9 |
| SLOPE | 60079 | 84.2 |
| VOL | 58717 | 82.3 |
| DIRECT | 58062 | 81.4 |
| FAIL_DEPTH | 50489 | 70.8 |
| HS_HEIGHT | 50453 | 70.7 |
| HD_AVE | 46342 | 65.0 |
| FAN_HEIGHT | 44436 | 62.3 |
| AGE | 42388 | 59.4 |
| MOVE_CLASS | 42357 | 59.4 |
| TYPE_MOVE | 42383 | 59.4 |
| MOVE_CODE | 42271 | 59.3 |
| CONFIDENCE | 42127 | 59.1 |
| GEOL | 41432 | 58.1 |
| HS_IS1 | 38187 | 53.5 |
| IS1_IS2 | 37122 | 52.1 |
| IS2_IS3 | 36299 | 50.9 |
| IS3_IS4 | 35940 | 50.4 |
| MAP_UNIT_L | 34199 | 48.0 |
| DEEP_SHAL | 29868 | 41.9 |
| NAME | 4088 | 5.7 |
| DATE_MOVE | 3932 | 5.5 |
| DATE_RANGE | 386 | 0.5 |
| YEAR | 265 | 0.4 |
| MONTH | 81 | 0.1 |
| DAY | 42 | 0.1 |
| REACTIVATION | 21 | 0.0 |
New Columns#
For filtering and aligning with the other cascadia datasets, we are computing some new columns. They will all start with the prefix “filter_”:
Material: [Debris, Earth, Rock, Complex, Water, Submarine]
Mouvement: [Flow, Complex, Slide, Slide-Rotational, Slide-Translational, Avalanche, Flood, Deformation, Topple, Spread, Submarine]
Confidence: [High, Medium, Low]
Dataset link: URL to dataset
Reference: Actual reference from the original data collection
the original dataset is concerved
Later in the post processing notebook, we will add more columns from external datasets
numerical_cols = deposits.select_dtypes(include=['number']).columns.tolist()
non_numerical_cols = deposits.select_dtypes(exclude=['number']).columns.tolist()
print("Numerical Columns:")
for col in numerical_cols:
print(f" - {col}")
print("\nNon-Numerical Columns:")
for col in non_numerical_cols:
print(f" - {col}")
Numerical Columns:
- SLOPE
- HS_HEIGHT
- FAN_HEIGHT
- FAIL_DEPTH
- HS_IS1
- IS1_IS2
- IS2_IS3
- IS3_IS4
- HD_AVE
- DIRECT
- AREA
- VOL
- YEAR
- Shape_Length
- Shape_Area
Non-Numerical Columns:
- UNIQUE_ID
- TYPE_MOVE
- MOVE_CLASS
- MOVE_CODE
- CONFIDENCE
- AGE
- DATE_MOVE
- NAME
- GEOL
- DEEP_SHAL
- REF_ID_COD
- MAP_UNIT_L
- DESCRIPTION
- DATE_RANGE
- REACTIVATION
- MONTH
- DAY
- geometry
Out of the above columns we have to change MOVE_CLASS, MOVE_CODE, CONFIDENCE,
Changed Columns#
Confidence#
Old Confidence Level#
print("\nValue counts for 'CONFIDENCE':")
print(deposits['CONFIDENCE'].value_counts())
plt.figure(figsize=(8, 6))
confidence_counts = deposits['CONFIDENCE'].value_counts()
sns.barplot(x=confidence_counts.index, y=confidence_counts.values, palette='coolwarm', hue=confidence_counts.index)
plt.title('Distribution of Confidence Levels', fontsize=16)
plt.xlabel('Confidence Level', fontsize=12)
plt.ylabel('Number of Deposits', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Value counts for 'CONFIDENCE':
CONFIDENCE
Moderate (11-29) 21774
High (=>30) 14541
Low (=<10) 5723
Moderate (20-30) 46
High (>30) 26
Low (<20) 10
Moderate (11-29) 5
High (=<30) 1
Moderate (15-29) 1
Name: count, dtype: int64
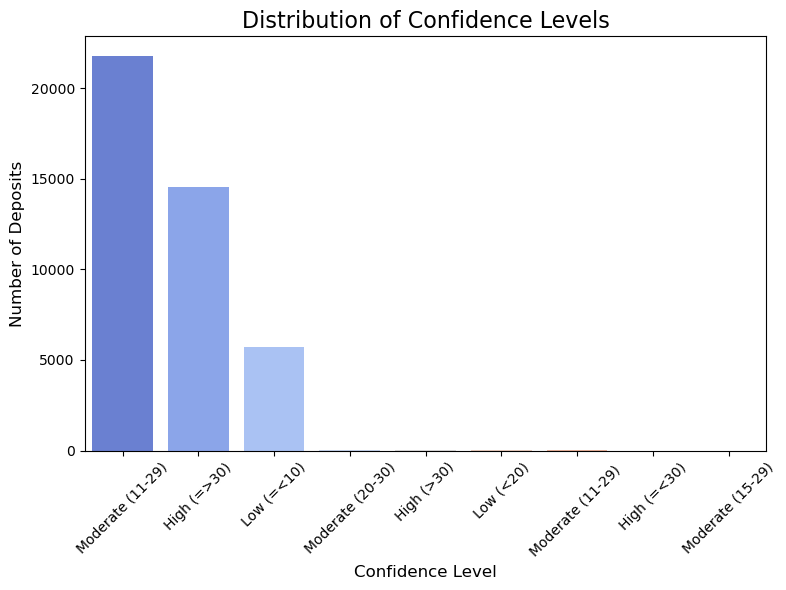
Here we have a lot of different confidence ranges. We only consider the major class not the ranges. So, values having low will be low and moderate will be moderate even if there is no class conflicts.
We make this decision because there are only a few data points that fall outside the three major classes. So, we try to align this extremely small minority into major classes.
New Confidence Level#
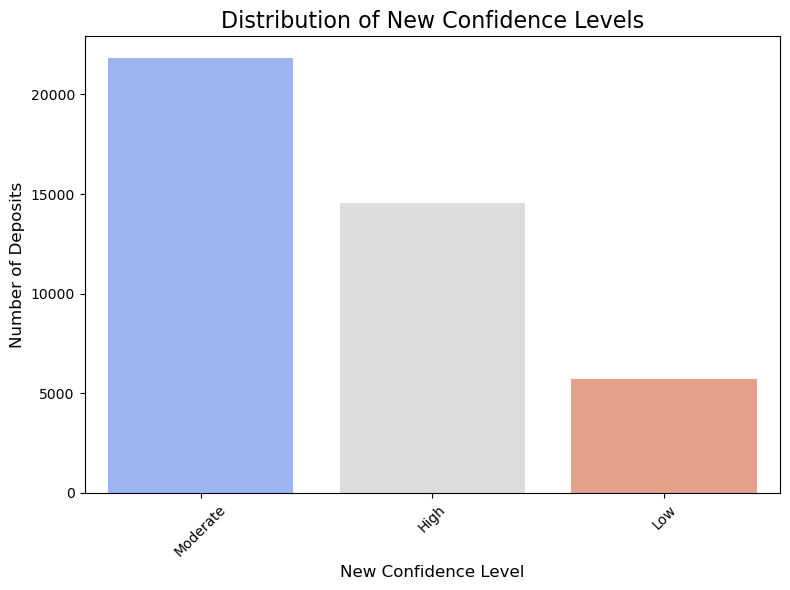
deposits['filter_CONFIDENCE'] = deposits['CONFIDENCE'].str.extract(r'^(High|Moderate|Low)')
print("Value counts for 'NEW_CONFIDENCE':")
print(deposits['filter_CONFIDENCE'].value_counts())
Value counts for 'NEW_CONFIDENCE':
filter_CONFIDENCE
Moderate 21826
High 14568
Low 5733
Name: count, dtype: int64
A quick math show that we have assigned the correct number of landslide deposits to each class.
plt.figure(figsize=(8,6))
new_confidence_counts = deposits['filter_CONFIDENCE'].value_counts()
sns.barplot(x=new_confidence_counts.index, y=new_confidence_counts.values, palette='coolwarm', hue=new_confidence_counts.index)
plt.title('Distribution of New Confidence Levels', fontsize=16)
plt.xlabel('New Confidence Level', fontsize=12)
plt.ylabel('Number of Deposits', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
MOVE CODE#
# print("\nValue counts for 'MOVE_CODE':")
# print(deposits['MOVE_CODE'].value_counts())
print("MOVE_CODE counts (sorted by frequency):")
move_code_counts = deposits['MOVE_CODE'].value_counts()
sorted_move_codes = move_code_counts.sort_values(ascending=False)
for move_code, count in sorted_move_codes.items():
print(f"{move_code}: {count}")
print() # Empty line for readability
MOVE_CODE counts (sorted by frequency):
DFL: 12752
EFL: 6919
RS-R+EFL: 4518
RS-R: 4407
RFL+EFL: 2948
RS-T: 2830
DS-T: 1800
RFL: 1665
RS-T+EFL: 798
ES-R: 777
ES-R+EFL: 736
RF: 733
ES-T: 270
ES-R + EFL: 145
DS-R: 132
RS-T+RS-R: 73
RS-R+RS-T+EFL: 68
RS-R+RS-T: 66
C: 61
RS-T+RS-R+EFL: 51
ES-R-EFL: 36
RS-T+ES-R+EFL: 34
ES-T+EFL: 29
EF: 26
RFL+RF: 25
EFL+RS-R: 19
RT+EFL: 18
RS-R+RFL: 15
RF+DS-T: 15
DS-R-DFL: 13
RFL+EF: 13
C-EFL: 12
RFL+DFL: 12
RS-T+RFL: 12
EFL+DFL: 12
C+RS-R+EFL: 11
DS-R+DFL: 11
DS-T-DFL: 9
C+RS-T+EFL: 9
RF+EF: 9
RS-R-DFL: 9
RS-R+EFL+RF: 8
RFL+RS-R: 8
EFL+RS-T: 7
RF+RS-T: 7
RS-R+DFL: 7
RFL+RS-T: 5
RS-R-EFL: 4
DS-T+DFL: 4
RS-R+ES-T+EFL: 4
RS-T+RF: 3
EFL+RF: 3
RS-R+ES-R: 3
ES-T+ES-R: 3
RS-T+RS-T: 3
DFL+EFL: 3
ES-R-DFL: 3
RF : 3
EFL+EFL: 3
RS-R+RF+EFL: 2
EFL
EFL
EFL: 2
DS-T+RS-T: 2
RS-T+EFL+RF: 2
ELF: 2
RF+EFL: 2
ES-R+EF: 2
RS-R_EFL: 2
RS-T+DFL: 2
DSP: 2
RS_T: 2
RS-R+RFL+EFL: 2
ES-R+DFL: 1
RS-R-RS-T: 1
RS-T+RS-R-EFL: 1
DFL-ES-R: 1
RS-T-DFL: 1
RS-R+RS-T-EFL: 1
ESL+EFL: 1
EFL
EFL: 1
DS-R-EFL: 1
RS-T+EFFL: 1
RF+DS-T+DF: 1
ES-R+ES-T+EFL: 1
RFL+RS-T+EFL: 1
RS-T+RS-R+RFL: 1
DS_R: 1
RS-T+RF+EFL: 1
RFL+EFL+RS-R: 1
RFL+RS-R+EFL: 1
RS-R+RS-T+DFL: 1
DS-R+DS-T: 1
C-ES+EFL: 1
EFL+ES-T: 1
EFL+RS_R: 1
DS-R+RS-R: 1
RS-T+RFL+EFL: 1
RS-R+RS_T+EFL: 1
RS-R+EFL+RFL: 1
DS-T+EFL: 1
ES-T+RS-T: 1
RS-R+DS-R: 1
RFL+RS-R+RS-T: 1
RFL+EFL_RS-R: 1
DFL-DS-R: 1
EFL : 1
RS-T+EFL_RS-R: 1
ES-R+RFL: 1
RS-T+EFL
RS-R+EFL: 1
RS-T+DS-T: 1
RT+ET: 1
EFL_RS-R: 1
EFL
RS-R+EFL: 1
RS-T+RS-R_EFL: 1
RS-T+RS-R+EFL+RF: 1
EFS-R+EFL: 1
DFL+RS+RF: 1
EFL-RFL: 1
TS-T: 1
DF+RF: 1
ES-R+ES-T: 1
RS-T+EFL+RS-R: 1
TS-T+RS-R+EFL: 1
RS-T+RS-R+EF : 1
RS-T : 1
RS-R+RS-R: 1
ES: 1
ES-R_EFL: 1
RS-T+EFLS: 1
C+RS-R+ES-T: 1
RS-T+RS-R+EF: 1
C+RS-R+DFL: 1
ES-R : 1
RS-R+RFL+DFL: 1
RS-R+DSP: 1
DFL
: 1
RF+RFL: 1
RF+RS-R: 1
RS-R : 1
RS-R + EFL: 1
deposits['MOVE_CODE'] = deposits['MOVE_CODE'].str.replace(r'\s+', '', regex=True)
# Get value counts for the cleaned codes
print("\nCleaned MOVE_CODE counts (sorted by frequency):")
clean_move_code_counts = deposits['MOVE_CODE'].value_counts()
sorted_clean_codes = clean_move_code_counts.sort_values(ascending=False)
for move_code, count in sorted_clean_codes.items():
print(f"{move_code}: {count}")
print() # Empty line for readability
Cleaned MOVE_CODE counts (sorted by frequency):
DFL: 12753
EFL: 6920
RS-R+EFL: 4519
RS-R: 4408
RFL+EFL: 2948
RS-T: 2831
DS-T: 1800
RFL: 1665
ES-R+EFL: 881
RS-T+EFL: 798
ES-R: 778
RF: 736
ES-T: 270
DS-R: 132
RS-T+RS-R: 73
RS-R+RS-T+EFL: 68
RS-R+RS-T: 66
C: 61
RS-T+RS-R+EFL: 51
ES-R-EFL: 36
RS-T+ES-R+EFL: 34
ES-T+EFL: 29
EF: 26
RFL+RF: 25
EFL+RS-R: 19
RT+EFL: 18
RS-R+RFL: 15
RF+DS-T: 15
DS-R-DFL: 13
RFL+EF: 13
EFL+DFL: 12
RFL+DFL: 12
C-EFL: 12
RS-T+RFL: 12
C+RS-R+EFL: 11
DS-R+DFL: 11
RS-R-DFL: 9
RF+EF: 9
DS-T-DFL: 9
C+RS-T+EFL: 9
RS-R+EFL+RF: 8
RFL+RS-R: 8
RS-R+DFL: 7
RF+RS-T: 7
EFL+RS-T: 7
RFL+RS-T: 5
DS-T+DFL: 4
RS-R-EFL: 4
RS-R+ES-T+EFL: 4
ES-R-DFL: 3
EFL+EFL: 3
RS-T+RS-T: 3
DFL+EFL: 3
EFL+RF: 3
RS-R+ES-R: 3
RS-T+RF: 3
ES-T+ES-R: 3
ELF: 2
DS-T+RS-T: 2
RS-T+RS-R+EF: 2
RS-R+RF+EFL: 2
EFLEFLEFL: 2
RF+EFL: 2
ES-R+EF: 2
RS-T+EFL+RF: 2
RS_T: 2
RS-R+RFL+EFL: 2
RS-R_EFL: 2
RS-T+DFL: 2
DSP: 2
DS-R-EFL: 1
DS_R: 1
RS-R+RS-T+DFL: 1
EFL-RFL: 1
DFL-ES-R: 1
DFL-DS-R: 1
RF+DS-T+DF: 1
EFLEFL: 1
ES-R+ES-T+EFL: 1
DS-R+RS-R: 1
RS-T+RF+EFL: 1
RT+ET: 1
RS-T-DFL: 1
RS-T+EFFL: 1
RS-R+RS-T-EFL: 1
ES-R+DFL: 1
RS-R+DSP: 1
RFL+RS-T+EFL: 1
RS-T+RS-R+RFL: 1
RFL+EFL+RS-R: 1
RS-R+RS_T+EFL: 1
RFL+RS-R+RS-T: 1
RS-R+DS-R: 1
ES-T+RS-T: 1
DS-T+EFL: 1
RS-R+EFL+RFL: 1
RS-T+RFL+EFL: 1
RFL+RS-R+EFL: 1
RS-T+EFL+RS-R: 1
EFL+RS_R: 1
RS-R+RS-R: 1
RS-T+RS-R-EFL: 1
DF+RF: 1
RS-T+EFLS: 1
ES-R_EFL: 1
RS-T+DS-T: 1
RS-T+EFLRS-R+EFL: 1
EFS-R+EFL: 1
RS-R+RFL+DFL: 1
RFL+EFL_RS-R: 1
ESL+EFL: 1
RS-T+EFL_RS-R: 1
DS-R+DS-T: 1
EFL_RS-R: 1
EFLRS-R+EFL: 1
C+RS-R+ES-T: 1
TS-T: 1
C+RS-R+DFL: 1
RS-T+RS-R_EFL: 1
EFL+ES-T: 1
RF+RFL: 1
ES-R+RFL: 1
RS-T+RS-R+EFL+RF: 1
TS-T+RS-R+EFL: 1
RF+RS-R: 1
DFL+RS+RF: 1
ES-R+ES-T: 1
C-ES+EFL: 1
RS-R-RS-T: 1
ES: 1
MOVE CLASS#
The original Move Class contains the kind of materials involved and the mode of movement. We seperate those into seperate columns to make it more consistent with other existing datasets.
print("\nValue counts for 'MOVE_CLASS':")
move_class_counts = deposits['MOVE_CLASS'].value_counts()
move_class_counts = move_class_counts.sort_values(ascending=False)
for move_class, count in move_class_counts.items():
print(f"{move_class}: {count}")
print()
Value counts for 'MOVE_CLASS':
Debris Flow: 12753
Earth Flow: 7044
Complex: 6007
Rock Slide-Rotational: 5509
Rock Slide-Translational: 2445
Rock Flow: 1729
Debris Slide-Translational: 1650
Complex-Earth Slide-Rotational+Earth Flow: 826
Rock Fall: 732
Rock Slide - Translational: 511
Earth Slide - Rotational: 456
Rock Slide - Rotational: 443
Earth Slide-Rotational: 342
Complex-Rock Slide-Rotational+Earth Flow: 303
Earth Slide-Translational: 250
Rock Slide - Rotational+Earth Flow: 182
Complex-Rock Slide-rotational and Earth Flow: 171
Debris Slide - Translational: 150
Complex-Rock Slide-Translational+Earth Flow: 113
Complex Rock Slide - Translational & Earth Flow: 111
Debris Slide-Rotational: 110
Complex Rock Slide - Rotational & Earth Flow: 63
Rock Slide-Rotational+Earth Flow: 57
Combined Slump - Earth Flow: 37
Complex Earth Slide - Rotational & Earth Flow: 36
Earth Slide - Translational: 34
Rock Slide-Translational+Earth Flow: 33
Earth Fall: 25
Rock Slide - Translational+Earth Flow: 22
Complex-Rock Slide-R+Rock Slide-T+Earth Flow: 19
Debris Slide- Rotational: 18
Earth Slide- Rotational: 18
Rock Slide- Rotational: 14
Rock Fall + Debris Slide-Translational: 13
Debris Slide-Rotational+Debris Flow: 10
Combined Earth Slide-Rotational + Earth Flow: 10
Earth Slide-Rotational+Earth Flow: 9
Channelized Debris Flow Deposition: 8
Debris Slide - Rotational: 7
Rock Slide- Translational: 6
Rock Slide-Rotational and Earth Flow: 5
Earth Slide- Translational: 4
Rock Slide-Translational+ Earth Flow : 4
Rock Slide-Translational and Earthflow: 4
Rock Slide-Translational+ Earth Flow: 3
Debris Slide-Translational+Debris Flow: 3
Rock Slide- Rotational + Earth Flow: 3
Combined Rock Slide-Rotational + Earth Flow: 3
Rock Slide - Translational + Earth Flow: 3
Earth Flow+Earth Flow: 3
Earth Slide - Rotational+Earth Flow: 3
Complex- Rock Slide-Rotational+Earth Flow: 3
Earth Slide-Translational+Earth Flow: 2
Rock Slide- Rotational+Earth Flow: 2
Earth Flow+Rock Slide - Rotational: 2
Debris Spread: 2
Debris Slide- Translational: 2
Rock Fall + Debris Slide-Tanslational: 1
Rock Fall + Rock Slide- Translational: 1
Debris Flow : 1
Rock Slide - Rotational+Rock Slide - Translational: 1
Rock Slide - Rotational+Debris Spread: 1
Complex-Earth Flow+Rock Slide Rotational: 1
Rotational Slide (slump): 1
Rock Fall + Debris Slide: 1
Rock Fall + Debris Slide-Translational + DFlow: 1
Debris Fall: 1
Translational Slide: 1
Complex-Debris Slide-Rotational+Debris Flow: 1
Rock Slide - Rotational+Rock Slide - Rotational: 1
Debris Slide-Transtional+Debris Flow: 1
Rock Slide-Translational+Rotational+Earth Flow: 1
Rock Slide-Rotational+Rock Flow: 1
Debris Slide-Rotiational: 1
Rock Slide- Translational+Rock Slide-Rotational: 1
Rock Slide-Translational and Rock Fall: 1
Debris Flow+ Earth Flow: 1
Debrs Flow: 1
Rock Fall and Rock Slide-Rotational: 1
Complex- Earth Flow+Debris Flow: 1
Earth Slide- Rotational : 1
Earth Topple: 1
Earth Spread: 1
Earth Slide - Rotational : 1
Rockslide translational+Earth Flow: 1
Rock Slide-Translational, Earth flow: 1
Earth flow: 1
Seperate out Materials involved#
import re
import pandas as pd
deposits['filter_MATERIAL'] = ''
def extract_materials(move_class_str):
# Return NaN for empty or null values instead of 'Other'
# This is needed since a lot of the MOVE_CLASS values are empty
if pd.isna(move_class_str) or str(move_class_str).strip() == '':
return pd.NA
move_class_str = str(move_class_str).lower()
# Fix common typos
move_class_str = move_class_str.replace('debrs', 'debris')
move_class_str = move_class_str.replace('rockslide', 'rock slide')
materials = []
# There is one Rotational Slide (slump): 1 that will be labelled as Earth
earth_pattern = r'earth|slump'
# From PMags.com Talus are bigger rocks providing slightly better traction
rock_pattern = r'rock|talus'
debris_pattern = r'debr'
# Check for each material type
if re.search(earth_pattern, move_class_str, re.IGNORECASE):
materials.append('Earth')
if re.search(rock_pattern, move_class_str, re.IGNORECASE):
materials.append('Rock')
if re.search(debris_pattern, move_class_str, re.IGNORECASE):
materials.append('Debris')
# Handle special case for "Complex" without specific material
if 'complex' in move_class_str.lower() and len(materials) == 0:
return 'Complex'
# If no materials found but the field is not empty, categorize as 'Other'
if not materials:
return 'Other'
# Join all found materials with '+'
# Sort to ensure consistent ordering
return '+'.join(sorted(materials))
# Apply the function to create a new column
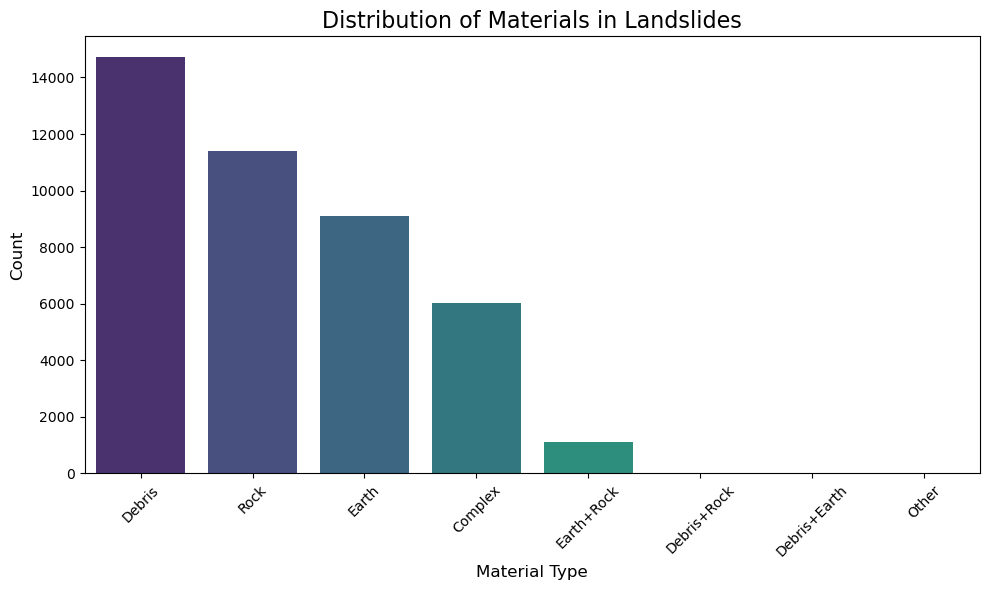
deposits['filter_MATERIAL'] = deposits['MOVE_CLASS'].apply(extract_materials)
print("\nValue counts for 'MATERIAL' (including nulls):")
material_counts_final = deposits['filter_MATERIAL'].value_counts(dropna=False)
print(material_counts_final)
# Plot distribution excluding NaN values
plt.figure(figsize=(10, 6))
non_null_counts = deposits['filter_MATERIAL'].value_counts()
sns.barplot(x=non_null_counts.index, y=non_null_counts.values,
palette='viridis', hue=non_null_counts.index, legend=False)
plt.title('Distribution of Materials in Landslides', fontsize=16)
plt.xlabel('Material Type', fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Value counts for 'MATERIAL' (including nulls):
filter_MATERIAL
<NA> 28961
Debris 14719
Rock 11396
Earth 9105
Complex 6007
Earth+Rock 1110
Debris+Rock 17
Debris+Earth 2
Other 1
Name: count, dtype: int64
Seperate out Modes of Movement#
import re
import pandas as pd
def extract_movement_class(move_class_str):
# Return NaN for empty or null values
# This is needed since a lot of the MOVE_CLASS values are empty
if pd.isna(move_class_str) or str(move_class_str).strip() == '':
return pd.NA
move_class_str = str(move_class_str).lower()
# Fix some typos and standardize formatting
move_class_str = move_class_str.replace('debrs', 'debris')
move_class_str = move_class_str.replace('rotiational', 'rotational')
move_class_str = move_class_str.replace('transtional', 'translational')
move_class_str = move_class_str.replace('tanslational', 'translational')
movement_classes = []
# Check for complex first (may contain other movement types)
if 'complex' in move_class_str:
movement_classes.append('Complex')
# Check for slide types
if 'slide' in move_class_str:
if 'rotational' in move_class_str or 'slump' in move_class_str:
movement_classes.append('Slide-Rotational')
elif 'translational' in move_class_str:
movement_classes.append('Slide-Translational')
else:
movement_classes.append('Slide')
# Check for flow
if 'flow' in move_class_str:
movement_classes.append('Flow')
# Check for fall
if 'fall' in move_class_str:
movement_classes.append('Fall')
# Check for spread
if 'spread' in move_class_str:
movement_classes.append('Spread')
# Check for topple
if 'topple' in move_class_str:
movement_classes.append('Topple')
# Check for avalanche
if 'avalanche' in move_class_str:
movement_classes.append('Avalanche')
# If no movement class was identified but the string isn't empty
if not movement_classes:
return 'Other'
# Join all identified movement classes with '+'
return '+'.join(movement_classes)
# Apply the function to create a new column
deposits['filter_MOVEMENT'] = deposits['MOVE_CLASS'].apply(extract_movement_class)
print("\nValue counts for 'MOVEMENT':")
movement_counts = deposits['filter_MOVEMENT'].value_counts(dropna=False)
print(movement_counts)
plt.figure(figsize=(12, 6))
non_null_counts = deposits['filter_MOVEMENT'].value_counts()
sns.barplot(x=non_null_counts.index, y=non_null_counts.values,
palette='viridis', hue=non_null_counts.index, legend=False)
plt.title('Distribution of Movement Classes', fontsize=16)
plt.xlabel('Movement Class', fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
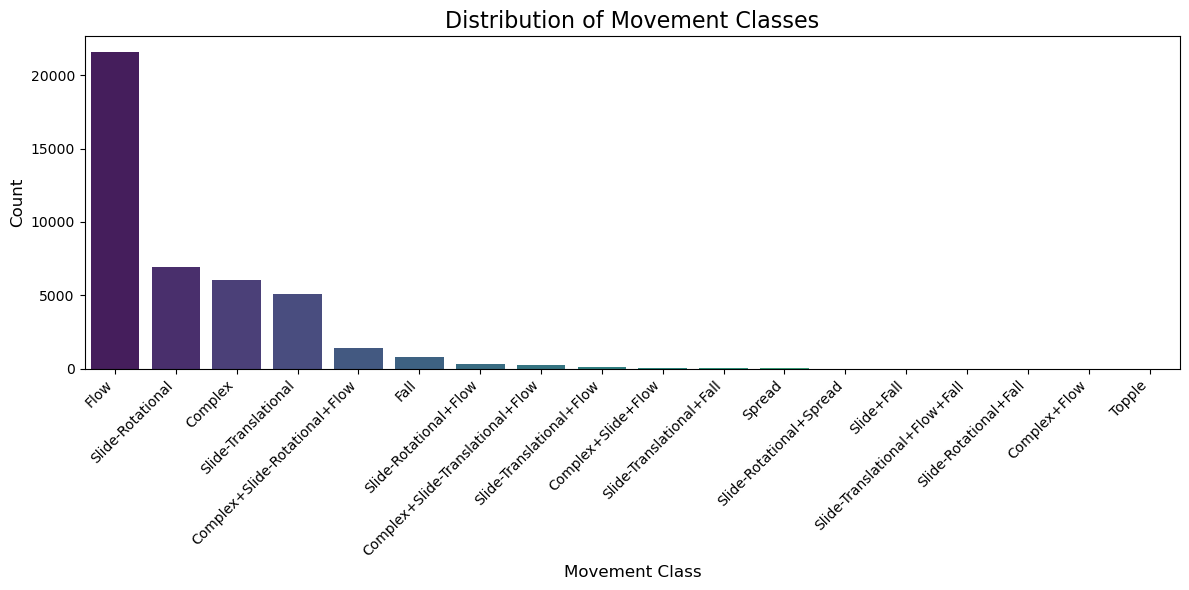
Value counts for 'MOVEMENT':
filter_MOVEMENT
<NA> 28961
Flow 21578
Slide-Rotational 6924
Complex 6007
Slide-Translational 5053
Complex+Slide-Rotational+Flow 1404
Fall 758
Slide-Rotational+Flow 288
Complex+Slide-Translational+Flow 224
Slide-Translational+Flow 77
Complex+Slide+Flow 19
Slide-Translational+Fall 16
Spread 3
Slide-Rotational+Spread 1
Slide+Fall 1
Slide-Translational+Flow+Fall 1
Slide-Rotational+Fall 1
Complex+Flow 1
Topple 1
Name: count, dtype: int64
Check all new columns#
print(deposits.dtypes)
UNIQUE_ID object
TYPE_MOVE object
MOVE_CLASS object
MOVE_CODE object
CONFIDENCE object
AGE object
DATE_MOVE object
NAME object
GEOL object
SLOPE float32
HS_HEIGHT float32
FAN_HEIGHT float32
FAIL_DEPTH float32
DEEP_SHAL object
HS_IS1 float32
IS1_IS2 float32
IS2_IS3 float32
IS3_IS4 float32
HD_AVE float32
DIRECT float32
AREA float32
VOL float32
REF_ID_COD object
MAP_UNIT_L object
DESCRIPTION object
YEAR float64
DATE_RANGE object
REACTIVATION object
MONTH object
DAY object
Shape_Length float64
Shape_Area float64
geometry geometry
filter_CONFIDENCE object
filter_MATERIAL object
filter_MOVEMENT object
dtype: object
Create a new DataFrame#
# Create a new GeoDataFrame
oregon_landslides = gpd.GeoDataFrame(deposits, geometry='geometry', crs=deposits.crs)
Inspect the new DataFrame#
# Verify the structure of the new GeoDataFrame
print("New GeoDataFrame shape:", oregon_landslides.shape)
print("\nColumn names:")
for col in oregon_landslides.columns:
print(f" - {col}")
# Display the first few rows to verify
oregon_landslides.head()
New GeoDataFrame shape: (71318, 36)
Column names:
- UNIQUE_ID
- TYPE_MOVE
- MOVE_CLASS
- MOVE_CODE
- CONFIDENCE
- AGE
- DATE_MOVE
- NAME
- GEOL
- SLOPE
- HS_HEIGHT
- FAN_HEIGHT
- FAIL_DEPTH
- DEEP_SHAL
- HS_IS1
- IS1_IS2
- IS2_IS3
- IS3_IS4
- HD_AVE
- DIRECT
- AREA
- VOL
- REF_ID_COD
- MAP_UNIT_L
- DESCRIPTION
- YEAR
- DATE_RANGE
- REACTIVATION
- MONTH
- DAY
- Shape_Length
- Shape_Area
- geometry
- filter_CONFIDENCE
- filter_MATERIAL
- filter_MOVEMENT
| UNIQUE_ID | TYPE_MOVE | MOVE_CLASS | MOVE_CODE | CONFIDENCE | AGE | DATE_MOVE | NAME | GEOL | SLOPE | ... | DATE_RANGE | REACTIVATION | MONTH | DAY | Shape_Length | Shape_Area | geometry | filter_CONFIDENCE | filter_MATERIAL | filter_MOVEMENT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | WASH_CO2 | Flow | Debris Flow | DFL | High (=>30) | Historic (<150yrs) | vol.M.cr.gr.nd.nd.bas | 4.256579 | ... | None | None | None | None | 447.239405 | 11291.764767 | MULTIPOLYGON (((699810 1325184.192, 699822.282... | High | Debris | Flow | ||
| 1 | WASH_CO3 | Flow | Debris Flow | DFL | High (=>30) | Historic (<150yrs) | vol.M.cr.gr.nd.nd.bas | 3.350513 | ... | None | None | None | None | 455.775817 | 13701.014637 | MULTIPOLYGON (((699860.473 1325401.027, 699873... | High | Debris | Flow | ||
| 2 | WASH_CO4 | Flow | Debris Flow | DFL | High (=>30) | Historic (<150yrs) | vol.M.cr.gr.nd.nd.bas | 5.811321 | ... | None | None | None | None | 568.959463 | 14879.315815 | MULTIPOLYGON (((700295.984 1325083.866, 700283... | High | Debris | Flow | ||
| 3 | WASH_CO5 | Flow | Debris Flow | DFL | High (=>30) | Historic (<150yrs) | sed.Q.qsd.mf.nd.nd.fine | 5.413578 | ... | None | None | None | None | 591.097110 | 20034.804942 | MULTIPOLYGON (((700696.889 1325351.537, 700659... | High | Debris | Flow | ||
| 4 | WASH_CO6 | Flow | Debris Flow | DFL | High (=>30) | Historic (<150yrs) | vol.M.cr.gr.nd.nd.bas | 13.638928 | ... | None | None | None | None | 391.627031 | 8462.716893 | MULTIPOLYGON (((699242.636 1321687.547, 699279... | High | Debris | Flow |
5 rows × 36 columns
Inspect References inside Deposits Layer#
print("Inspecting references in oregon_landslides:")
print(f"Total records: {len(oregon_landslides)}")
print(f"Records with REF_ID_COD: {oregon_landslides['REF_ID_COD'].notna().sum()}")
print(f"Records without REF_ID_COD: {oregon_landslides['REF_ID_COD'].isna().sum()}")
print("\nTop 10 most common references:")
ref_counts = oregon_landslides['REF_ID_COD'].value_counts().head(10)
for ref_id, count in ref_counts.items():
print(f"{ref_id}: {count}")
print(f"\nTotal unique references: {oregon_landslides['REF_ID_COD'].nunique()}")
print("\nSample of reference IDs:")
sample_refs = oregon_landslides['REF_ID_COD'].dropna().unique()[:10]
for ref in sample_refs:
print(f" - {ref}")
Inspecting references in oregon_landslides:
Total records: 71318
Records with REF_ID_COD: 71318
Records without REF_ID_COD: 0
Top 10 most common references:
HairRW2021: 5017
CalhNC2020a: 4096
BurnWJ2017a: 2986
BurnWJ2012a: 2837
BurnWJ2023: 2693
BurnWJ2014: 2483
BurnWJ2021: 2228
McClJD2021b: 2122
CALHNC2020: 2098
BurnWJ2018: 1969
Total unique references: 346
Sample of reference IDs:
- HairRW2021
- BurnWJ2023
- BurnWJ2010a
- BurnWJ2010b
- BurnWJ2010c
- BurnWJ2009b
- BurnWJ2010d
- MertSA2007a
- McClJD2010
- HladFR2007
Inspect References Layer#
# Load and inspect the References layer
references = gpd.read_file(gdb_dir, layer="References")
print("References layer shape:", references.shape)
print("\nReferences layer columns:")
for col in references.columns:
print(f" - {col}")
print("\nFirst few rows of References:")
print(references.head())
print("\nData types:")
print(references.dtypes)
# Check for common reference identifiers between deposits and references
print("\nUnique REF_ID_COD values in deposits (first 10):")
print(deposits['REF_ID_COD'].unique()[:10])
print("\nUnique REF_ID_COD values in references:")
print(references['REF_ID_COD'].unique())
# Check if there's overlap
common_refs = set(deposits['REF_ID_COD'].dropna()) & set(references['REF_ID_COD'].dropna())
print(f"\nNumber of common reference IDs: {len(common_refs)}")
print("Sample common reference IDs:", list(common_refs)[:5])
References layer shape: (376, 4)
References layer columns:
- REF_ID_COD
- SCALE
- REFERENCE
- DATE
First few rows of References:
REF_ID_COD SCALE REFERENCE \
0 AchJA1991 1:24,000 Ach, J.A., Bateson, J.T., 1991, Geologic map o...
1 AllaJC2001 1:25,000 Allan, J.C.; Priest, G.R., 2001, Evaluation of...
2 AlleJE1988 1:24,000 Allen, J.E., 1988, Geologic Hazards in the Col...
3 AndeJL1978 1:24,000 Anderson, J. L., 1978, The stratigraphy and st...
4 AshlRP1966 1:21,100 Ashley, R.P., 1966, Metamorphic petrology and ...
DATE
0 1991
1 2001
2 1988
3 1978
4 1966
Data types:
REF_ID_COD object
SCALE object
REFERENCE object
DATE object
dtype: object
Unique REF_ID_COD values in deposits (first 10):
['HairRW2021' 'BurnWJ2023' 'BurnWJ2010a' 'BurnWJ2010b' 'BurnWJ2010c'
'BurnWJ2009b' 'BurnWJ2010d' 'MertSA2007a' 'McClJD2010' 'HladFR2007']
Unique REF_ID_COD values in references:
['AchJA1991' 'AllaJC2001' 'AlleJE1988' 'AndeJL1978' 'AshlRP1966'
'BacoCRUnpub' 'BaldEM1952' 'BaldEM1955' 'BaldEM1956' 'BaldEM1961'
'BaldEM1969' 'BaldEM1973' 'BaraP1991' 'BarnCG1978' 'BeauJD1973hazards'
'BeauJD1974ahazards' 'BeauJD1974bhazards' 'BeauJD1975hazards'
'BeauJD1976hazards' 'BeauJD1977ahazards' 'BeauJD1977bhazards'
'BelaJL1981' 'BelaJL1982' 'BestEA2002Figure3' 'BingNJ1984' 'BlacGL1987'
'BlacGL1995' 'BlacGL2000' 'BrikTH1983' 'BroeL1995' 'BrooHC1976'
'BrooHC1977a' 'BrooHC1977cplateA' 'BrooHC1977cplateB' 'BrooHC1979a'
'BrooHC1979b' 'BrooHC1979c' 'BrooHC1982a' 'BrooHC1982b' 'BrooHC1983'
'BrooHC1984' 'BrooHCUnpubB' 'BrowCE1966a' 'BrowCE1966b' 'BrowCE1977'
'BrowDE1980aplate1' 'BrowDE1980aplate2' 'BrowDE1980aplate3'
'BrowDE1980aplate4' 'BrowDE1980b' 'BrowDE1980c' 'BrowDE1980d'
'BrowDE1982' 'BrowME1982' 'BurnSF1997' 'BurnWJ2009b' 'BurnWJ2010a'
'BurnWJ2010b' 'BurnWJ2010c' 'BurnWJ2010d' 'BurnWJ2011' 'BussC2006'
'CampVCunpubA' 'CampVCunpubB' 'CampVCunpubC' 'CampVCunpubD' 'ConrRM1991'
'CoxGM1977' 'CummJA1958' 'CunnCT1979' 'DickWR1965easthalf'
'DickWR1965westhalf' 'DiggMF1991' 'DonaMM1992' 'DonaMM1993' 'ErikA2002'
'EvanJG1986a' 'EvanJG1987' 'EvanJG1989' 'EvanJG1990' 'EvanJG1991'
'EvanJG1993' 'EvanJG1995' 'EvanJG2001' 'EvarRC2002' 'EvarRC2004'
'FEMA2006' 'FernML1983' 'FernML1984' 'FernML1987' 'FernML1993a'
'FernML1993b' 'FernML2001a' 'FernML2001b' 'FernML2006a' 'FernML2006b'
'FernML2006c' 'FernML2010' 'FernMLUnpubB' 'GrayF1980' 'GrayF1982'
'GreeRC1972a' 'HaddGH1959' 'HalePO1975' 'HammPE1982' 'HampER1972'
'HaucSM1962' 'HeriCW1981' 'HewiSL1970' 'HladFR1992' 'HladFR1993'
'HladFR1994' 'HladFR1996' 'HladFR1998' 'HladFR1999' 'HladFR2006'
'HladFR2007' 'HofmRJ2000' 'HoodNF1997' 'HoovL1963' 'HuggJW1978'
'JackJS1979' 'JacoR1985' 'JenkMDUnpub' 'JohaNP1972' 'JohnJA1994'
'JohnJA1995' 'JohnJA1998a' 'JohnJA1998b' 'KoroMA1987' 'LangVW1991'
'MacLJW1994plate1' 'MacLJW1994plate2' 'MacLNS1995sheet1'
'MacLNS1995sheet2' 'MaddT1965' 'MadiIP2006a' 'MadiIP2006b' 'MadiIP2007'
'MathAC1993' 'McclJD2006a' 'McclJD2006b' 'McClJD2010' 'McCoVSUnpubA'
'McCoVSUnpubB' 'MertSA2007a' 'MertSA2007b' 'MertSA2008' 'MertSA2009'
'MertSAUnpub' 'MillPR1984' 'MinoSA1987b' 'MinoSA1990a' 'MinoSA1990b'
'Misc_unpub' 'MoorR2004' 'MuntJK1969' 'MuntSR1978' 'MurrRB2001'
'MurrRB2006a' 'MurrRBUnpubA' 'MurrRBunpubB' 'NappJE1958' 'NichDK1989'
'NiemAR1985' 'NiemAR1990' 'NoblJB1979' 'OConJE2001' 'ODOT2011'
'OlesKF1971' 'OlivJA1981' 'OrrWN1986a' 'OrrWN1986b' 'OwenPC1977'
'PageNJ1977' 'PageNJ1981' 'PattRL1965' 'PertRK1976' 'PeteNV1976Redmond'
'PeteNV1980' 'PoguKR1999' 'Portland2011' 'PrieGR1982plate5'
'PrieGR1982plate6' 'PrieGR1983plate2' 'PrieGR1983plate3' 'PrieGR1987'
'PrieGR1988' 'PrieGR2000' 'PrieGR2004a' 'PrieGR2004b' 'ProsHJ1967'
'RampL1961' 'RampL1986' 'RitcB1987' 'RobaRC1987' 'RobiPT1975'
'RobyTL1977' 'RytuJJ1982a' 'RytuJJ1983b' 'RytuJJ1983c' 'RytuJJ1983e'
'RytuJJ1983g' 'RytuJJ1983h' 'SchlHG1967Plate3' 'SchlHG1972hazards'
'SchlHG1973' 'SchlHG1974' 'SchlHG1974hazards' 'SchlHG1975'
'SchlHG1979hazards' 'SchnDR1958' 'SchuMG1980' 'ScotWE1992' 'SherDR1988'
'SherDR1989' 'SherDR1991' 'SherDR1992' 'SherDR1994' 'SherDR1995'
'SherDR2000' 'SherDR2004' 'SmitGA1987a' 'SmitGA1987b' 'SmitGA1987c'
'SmitJG1982' 'SnavPD1976b' 'SnavPD1976c' 'SnavPD1996' 'SobiS2010'
'StimJP1988' 'StocAO1982' 'StroHR1980' 'SwanDA1969' 'SwanDA1981sheet1'
'SwanDA1981sheet2' 'SwanDA1981sheet3' 'SwanDA1983' 'SwinCM1968'
'ThayTP1956' 'ThayTP1966' 'ThayTP1967b' 'ThayTP1967c' 'ThayTP1981'
'ThomTH1981' 'ThorDJ1984' 'TolaTL1982' 'TolaTL1999sheet1'
'TolaTL2000sheet2' 'TravPL1977' 'TuckER1975' 'VandDB1988' 'WalkGW1963'
'WalkGW1965' 'WalkGW1966' 'WalkGW1967' 'WalkGW1968figure2'
'WalkGW1968figure3' 'WalkGW1979' 'WalkGW1980b' 'WalkGW1989' 'WalkGW2002'
'WangZ2001' 'WateAC1968a' 'WateAC1968b' 'WateAC1968c' 'WateAC1968d'
'WeidJP1980' 'WeisKW1984' 'WellFG1949' 'WellFG1953' 'WellRE1975'
'WellRE1983' 'WellRE1995' 'WellRE2000' 'WendDW1988' 'WethCE1960'
'WhitDL1994' 'WhitWH1964' 'WilcRE1966' 'WileTJ1991' 'WileTJ1993a'
'WileTJ1993bplate1' 'WileTJ2006a' 'WileTJ2006b' 'WileTJ2006c'
'WileTJ2007' 'WileTJunpub' 'WilkRM1986' 'WittRC2007' 'WittRC2009'
'WoodJD1976' 'YeatRS1996plate2a' 'YeatRS1996plate2b' 'YogoGM1985'
'YuleJD1996plate10' 'YuleJD1996plate11' 'YuleJD1996plate2'
'YuleJD1996plate8' 'YuleJD1996plate9' 'BurnWJ2011b' 'BurnWJ2011c'
'BurnWJ2012a' 'BurnWJ2012b' 'BurnWJ2012c' 'BurnWJ2012d' 'BurnWJ2012f'
'BurnWJ2012e' 'BurnWJ2012g' 'BurnWJ2012h' 'BurnWJ2012i' 'BurnWJ2012j'
'BurnWJ2012k' 'BurnWJ2012l' 'BurnWJ2012m' 'BurnWJ2012n' 'BurnWJ2012o'
'BurnWJ2012p' 'BurnWJ2011d' 'BurnWJ2013a' 'BurnWJ2012q' 'BurnWJ2012r'
'BurnWJunpub2013a' 'BurnWJ2013c' 'McClJD2012' 'BurnWJunpub2014'
'McClJDunpub2013' 'MickKA2012' 'WileTJ2011' 'BurnWJ2013d'
'MickKAunpub2012' 'BurnWJunpub2013b' 'McClJD2013' 'BurnWJunpub2011'
'BurnWJ2013b' 'WileTJ2014' 'MickKAunpub2014' 'BurnWJ2014' 'BurnWJ2013e'
'BurnWJ2015a' 'WileTJ2015' 'DirrS2015' 'BurnWJ2018' 'CalhNC2018'
'BurnWJ2009c' 'BurnWJ2015b' 'NiewCA2018' 'HousRA2018' 'MickKA2011'
'KossEunpub2019' 'BurnWJunpub2019' 'BurnWJ2010e' 'McClJD2019'
'MadiIP2019' 'BurnWJ2017a' 'BurnWJ2017' 'BeauJD1976' 'CalhNC2020'
'CalhNC2020a' 'BurnWJunpub2021' 'BurnWJ2021' 'BurnWJ2021a' 'BurnWJ2021b'
'BurnWJ2021c' 'BurnWJ2021d' 'BurnWJ2023' 'McClJD2021a' 'HousRA2021'
'BurnWJ2022' 'HairRW2021' 'McClJD2020' 'McClJD2020b' 'McClJD2023'
'McClJD2021b' 'WellRE2020' 'CalhNC2023']
Number of common reference IDs: 345
Sample common reference IDs: ['WileTJ2006a', 'CalhNC2018', 'WileTJ2014', 'BlacGL2000', 'BurnWJ2011d']
# Merge the references information into oregon_landslides
oregon_landslides = oregon_landslides.merge(
references[['REF_ID_COD', 'REFERENCE']],
on='REF_ID_COD',
how='left'
)
print("Successfully added REFERENCE column to oregon_landslides")
print(f"Records with references: {oregon_landslides['REFERENCE'].notna().sum()}")
print(f"Records without references: {oregon_landslides['REFERENCE'].isna().sum()}")
# Display a sample of the new column
print("\nSample references:")
sample_refs = oregon_landslides[oregon_landslides['REFERENCE'].notna()]['REFERENCE'].head(3)
for i, ref in enumerate(sample_refs):
print(f"{i+1}. {ref[:100]}...")
Successfully added REFERENCE column to oregon_landslides
Records with references: 69220
Records without references: 2098
Sample references:
1. Hairston-Porter, R., Madin, I., Burns, W., and Appleby, C., 2021, Landslide, coseismic liquefaction ...
2. Hairston-Porter, R., Madin, I., Burns, W., and Appleby, C., 2021, Landslide, coseismic liquefaction ...
3. Hairston-Porter, R., Madin, I., Burns, W., and Appleby, C., 2021, Landslide, coseismic liquefaction ...
print("Columns in oregon_landslides:")
for i, col in enumerate(oregon_landslides.columns):
print(f"{i+1:2d}. {col}")
Columns in oregon_landslides:
1. UNIQUE_ID
2. TYPE_MOVE
3. MOVE_CLASS
4. MOVE_CODE
5. CONFIDENCE
6. AGE
7. DATE_MOVE
8. NAME
9. GEOL
10. SLOPE
11. HS_HEIGHT
12. FAN_HEIGHT
13. FAIL_DEPTH
14. DEEP_SHAL
15. HS_IS1
16. IS1_IS2
17. IS2_IS3
18. IS3_IS4
19. HD_AVE
20. DIRECT
21. AREA
22. VOL
23. REF_ID_COD
24. MAP_UNIT_L
25. DESCRIPTION
26. YEAR
27. DATE_RANGE
28. REACTIVATION
29. MONTH
30. DAY
31. Shape_Length
32. Shape_Area
33. geometry
34. filter_CONFIDENCE
35. filter_MATERIAL
36. filter_MOVEMENT
37. REFERENCE
oregon_landslides['filter_DATASET_LINK'] = 'https://www.oregon.gov/dogami/slido/Pages/data.aspx'
oregon_landslides['filter_ORIGIN'] = 'OR'
oregon_landslides = oregon_landslides.rename(columns={'REFERENCE': 'filter_REFERENCE'})
Save into GeoJSON#
oregon_landslides.to_file("./processed_geojson/oregon_landslides_processed.geojson", driver="GeoJSON")
# oregon_landslides.to_file("oregon_landslides_processed.shp")
oregon_landslides.plot(figsize=(8, 6), edgecolor="k", linewidth=0.2)
plt.title("Oregon Landslide Inventory")
plt.axis("off")
plt.show()
oregon_landslides.columns
Index(['UNIQUE_ID', 'TYPE_MOVE', 'MOVE_CLASS', 'MOVE_CODE', 'CONFIDENCE',
'AGE', 'DATE_MOVE', 'NAME', 'GEOL', 'SLOPE', 'HS_HEIGHT', 'FAN_HEIGHT',
'FAIL_DEPTH', 'DEEP_SHAL', 'HS_IS1', 'IS1_IS2', 'IS2_IS3', 'IS3_IS4',
'HD_AVE', 'DIRECT', 'AREA', 'VOL', 'REF_ID_COD', 'MAP_UNIT_L',
'DESCRIPTION', 'YEAR', 'DATE_RANGE', 'REACTIVATION', 'MONTH', 'DAY',
'Shape_Length', 'Shape_Area', 'geometry', 'filter_CONFIDENCE',
'filter_MATERIAL', 'filter_MOVEMENT', 'filter_REFERENCE',
'filter_DATASET_LINK', 'filter_ORIGIN'],
dtype='object')