California Landslide Data Preprocessing#
Overview#
This notebook processes landslide data from california for integration with the Cascadia regional dataset.
Key Processing Steps:#
Load Dataset
Standardization: Add filtering column names and data types with unified schema
Export Processing: Save cleaned data as standardized GeoJSON
Initial Inspection#
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
gdf = gpd.read_file("../data/California/cgs_DC213.geojson")
len(gdf)
12909
# Show all columns when printing DataFrames
pd.set_option("display.max_columns", None)
pd.set_option("display.width", None)
gdf.head()
| sec_geol_unit_map_symb | SymSize | SHAPE.STArea() | SHAPE.STLength() | OBJECTID | creation_date | revision_date | geom_rev_date | geom_rev_staff | ls_id | ls_master | activity | init_type | subs_type | mvmt_mode | confidence | thickness | dir_mvmt | base_map | map_year | ls_data_source_type | ls_data_source_desc | prim_geol_unit_map_symb | prim_geol_unit_name | sec_geol_unit_name | geol_data_source | strike_az | dip | attitude_type | att_data_source | staff | peer_rev_staff | remarks | data_class | citable_product | mvmt_date_yr | mvmt_date_mon | mvmt_date_day | triggering_event | superseded | citable_product_url | gis_source | created_user | created_date | last_edited_user | last_edited_date | FeatID | display_class | source_layer_id | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | None | 2.858618 | 2299.895764 | 268.182677 | 1965 | 1362700800000 | None | None | None | Vent0770 | None | None | None | None | None | None | None | 150.0 | 2015.0 | None | Qsb | None | None | Tan, 2003 | 90.0 | 40.0 | bed | Tan/Dibblee | None | A | CGS Landslide Inventory Map in progress 2015 | None | None | None | None | N | None | G:\CGS\GM_Work\Landslide Inventories\StateLand... | None | NaN | None | NaN | 1965 | 2 | 13 | POLYGON ((-13276650.321 4068567.489, -13276652... | ||||
| 1 | None | 3.883193 | 9061.502229 | 777.839423 | 2611 | 1367366400000 | None | None | None | Vent1418 | None | None | None | None | None | None | None | 120.0 | 2015.0 | None | Qls developed in Tp | None | None | Tan, 2003 | NaN | NaN | None | None | None | A | CGS Landslide Inventory Map in progress 2015 | None | None | None | None | N | None | G:\CGS\GM_Work\Landslide Inventories\StateLand... | None | NaN | None | NaN | 2611 | 2 | 13 | POLYGON ((-13276837.792 4076551.465, -13276826... | ||||
| 2 | None | 5.290792 | 4525.327447 | 285.107144 | 3970 | 1450889472000 | None | None | None | None | None | df | None | None | None | None | 290.0 | None | NaN | IMG | None | None | None | None | None | NaN | NaN | None | None | None | None | None | C | CGS to CDF 92 | None | None | None | None | N | G:\CGS\GM_Work\Landslide Inventories\StateLand... | NROTH | 1.450983e+12 | NROTH | 1.450983e+12 | 3970 | 2 | 13 | POLYGON ((-13571751.348 4448987.266, -13571747... | ||
| 3 | None | 9.967204 | 23680.277869 | 791.939850 | 3971 | 1450889472000 | None | None | None | None | None | rs | None | None | None | None | 100.0 | None | NaN | IMG | None | None | None | None | None | NaN | NaN | None | None | None | None | None | C | CGS to CDF 92 | None | None | None | None | N | G:\CGS\GM_Work\Landslide Inventories\StateLand... | NROTH | 1.450983e+12 | NROTH | 1.450983e+12 | 3971 | 2 | 13 | POLYGON ((-13572747.205 4449035.828, -13572760... | ||
| 4 | None | 4.277160 | 2231.315528 | 173.893848 | 3972 | 1450889472000 | None | None | None | None | None | df | None | None | None | None | 220.0 | None | NaN | IMG | None | None | None | None | None | NaN | NaN | None | None | None | None | None | C | CGS to CDF 92 | None | None | None | None | N | G:\CGS\GM_Work\Landslide Inventories\StateLand... | NROTH | 1.450983e+12 | NROTH | 1.450983e+12 | 3972 | 2 | 13 | POLYGON ((-13572223.032 4449034.498, -13572217... |
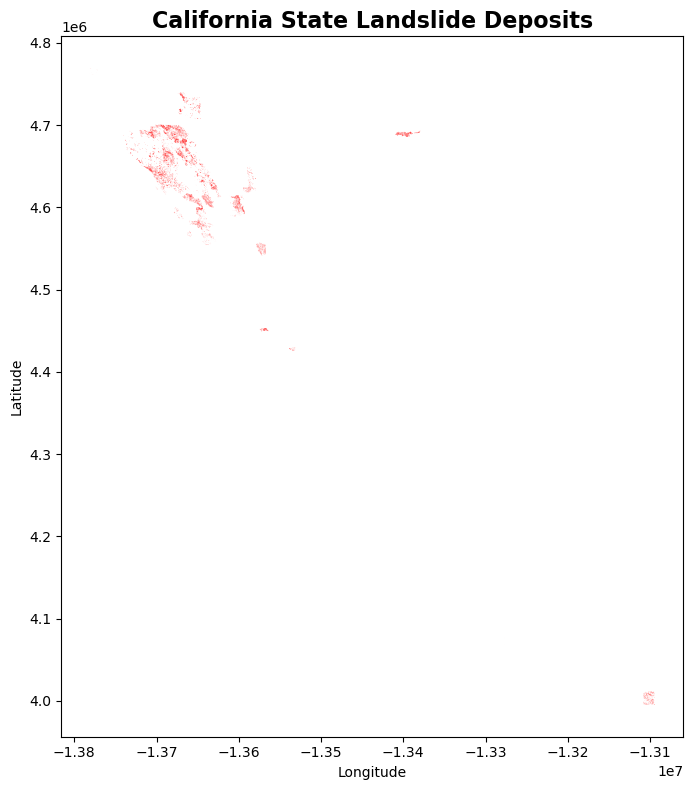
# Simple plot of landslide deposits
fig, ax = plt.subplots(figsize=(12, 8))
gdf.plot(ax=ax, alpha=0.7, color='red', markersize=0.5)
ax.set_title("California State Landslide Deposits", fontsize=16, fontweight='bold')
ax.set_xlabel("Longitude")
ax.set_ylabel("Latitude")
plt.tight_layout()
plt.show()
Analysis#
# Seperating deposits by column types
numerical_cols = gdf.select_dtypes(include=['number']).columns.tolist()
non_numerical_cols = gdf.select_dtypes(exclude=['number']).columns.tolist()
print("Numerical Columns:")
for col in numerical_cols:
print(f" - {col}")
print("\nNon-Numerical Columns:")
for col in non_numerical_cols:
print(f" - {col}")
Numerical Columns:
- SymSize
- SHAPE.STArea()
- SHAPE.STLength()
- OBJECTID
- creation_date
- dir_mvmt
- map_year
- strike_az
- dip
- created_date
- last_edited_date
- FeatID
- display_class
- source_layer_id
Non-Numerical Columns:
- sec_geol_unit_map_symb
- revision_date
- geom_rev_date
- geom_rev_staff
- ls_id
- ls_master
- activity
- init_type
- subs_type
- mvmt_mode
- confidence
- thickness
- base_map
- ls_data_source_type
- ls_data_source_desc
- prim_geol_unit_map_symb
- prim_geol_unit_name
- sec_geol_unit_name
- geol_data_source
- attitude_type
- att_data_source
- staff
- peer_rev_staff
- remarks
- data_class
- citable_product
- mvmt_date_yr
- mvmt_date_mon
- mvmt_date_day
- triggering_event
- superseded
- citable_product_url
- gis_source
- created_user
- last_edited_user
- geometry
New Columns#
Confidence#
We will convert the values into 3 main classes Moderate, High and Low to be more consistent with Washington and Oregon.
Raw Confidence Values#
print("Value Counts for Confidence:")
print(gdf['confidence'].value_counts())
Value Counts for Confidence:
confidence
d 2377
q 1405
p 394
c 3
h 2
o 1
Name: count, dtype: int64
Replacing empty strings with NaN#
# Normalize to H/M/L categories
# Assuming the original codes are single letters: p, d, q
mapping = {
"p": "High",
"d": "Medium",
"q": "Low"
}
# Apply the mapping (case-insensitive)
gdf["filter_CONFIDENCE"] = gdf["confidence"].str.lower().map(mapping).fillna("Unknown")
# Quick check
gdf[["filter_CONFIDENCE", "confidence"]].value_counts()
filter_CONFIDENCE confidence
Medium d 2377
Low q 1405
High p 394
Unknown c 3
h 2
o 1
Name: count, dtype: int64
Type#
Original Type#
type_counts = gdf['init_type'].value_counts()
print("\nValue Counts for Type:")
print(type_counts)
Value Counts for Type:
init_type
df 2171
rs 1717
ef 1696
ss 19
cl 16
q 3
d 1
Name: count, dtype: int64
Extracting Material from Type#
import pandas as pd
# --- 1) Allowed categories (must match your filter lists exactly) ---
KNOWN_MATERIALS = ["Debris", "Earth", "Rock", "Complex", "Water", "Submarine"]
KNOWN_MOVEMENTS = ["Flow", "Complex", "Slide", "Slide-Rotational", "Slide-Translational",
"Avalance", "Flood", "Deformation", "Topple", "Spread", "Submarine"]
# --- 2) Look-up tables (seed set; extend as needed for your dataset) ---
# Map mvmt_mode codes -> movement categories (one or more)
MVMT_MODE_MAP = {
"st": {"Slide", "Slide-Translational"},
"sr": {"Slide", "Slide-Rotational"},
"sc": {"Slide", "Complex"}, # compound slide
"fl": {"Flow"},
"av": {"Avalance"}, # keep your category spelling
"fd": {"Flood"},
"dp": {"Deformation"},
"tp": {"Topple"},
"sp": {"Spread"},
"sb": {"Submarine"},
}
# Map init/subs codes -> (materials, movement-hints)
# (Use both init_type and subs_type; union them.)
INIT_SUBS_MAP = {
"df": ({"Debris"}, {"Flow"}), # debris flow
"ef": ({"Earth"}, {"Flow"}), # earth flow
"rf": ({"Rock"}, {"Topple"}), # rock fall -> closest: Topple
"dl": ({"Debris"}, {"Slide"}), # debris slide
"el": ({"Earth"}, {"Slide"}), # earth slide
"rl": ({"Rock"}, {"Slide"}), # rock slide
"dg": ({"Complex"}, {"Deformation"}), # disrupted ground
"dn": ({"Debris"}, {"Flow"}), # debris fan (flow deposit)
"la": ({"Water", "Debris"}, {"Flow"}), # lahar (if present)
"cm": ({"Complex"}, {"Complex"}), # explicit complex (if present)
"sb": ({"Submarine"}, {"Submarine"}), # submarine (if present)
# add more codes here as you encounter them
}
def _codeset(v):
if pd.isna(v):
return set()
s = str(v).strip().lower()
# handle comma/semicolon separated combos if they occur
parts = [p.strip() for p in s.replace(";", ",").split(",") if p.strip()]
return set(parts) if parts else ({s} if s else set())
def infer_material_movement(row):
mats, movs = set(), set()
# mvmt_mode is the strongest movement signal
for code in _codeset(row.get("mvmt_mode")):
movs |= MVMT_MODE_MAP.get(code, set())
# init_type and subs_type inform both material and movement
for code in _codeset(row.get("init_type")) | _codeset(row.get("subs_type")):
m2, v2 = INIT_SUBS_MAP.get(code, (set(), set()))
mats |= m2
movs |= v2
# Keep only known categories to avoid typos
mats = [m for m in KNOWN_MATERIALS if m in mats]
movs = [m for m in KNOWN_MOVEMENTS if m in movs]
# Fallbacks: if nothing inferred, pick sensible defaults
if not mats:
mats = ["Complex"]
if not movs:
# If slide subtype present without generic 'Slide', add it
# (e.g., Slide-Rotational → also include Slide for your filters)
movs = ["Slide"]
# Return as semicolon-separated lists to allow combinations
return pd.Series({
"material": "; ".join(mats),
"movement": "; ".join(movs),
})
# --- 5) Apply inference ---
gdf[["filter_MATERIAL", "filter_MOVEMENT"]] = gdf.apply(infer_material_movement, axis=1)
# --- 6) Quick QA checks ---
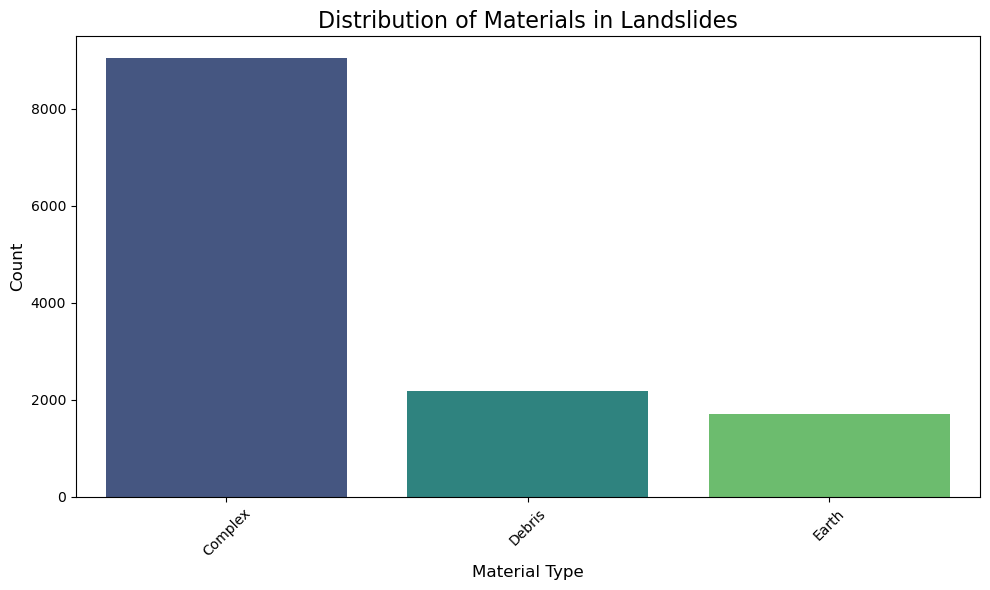
print("Material distribution:")
print(gdf["filter_MATERIAL"].value_counts().head(15), "\n")
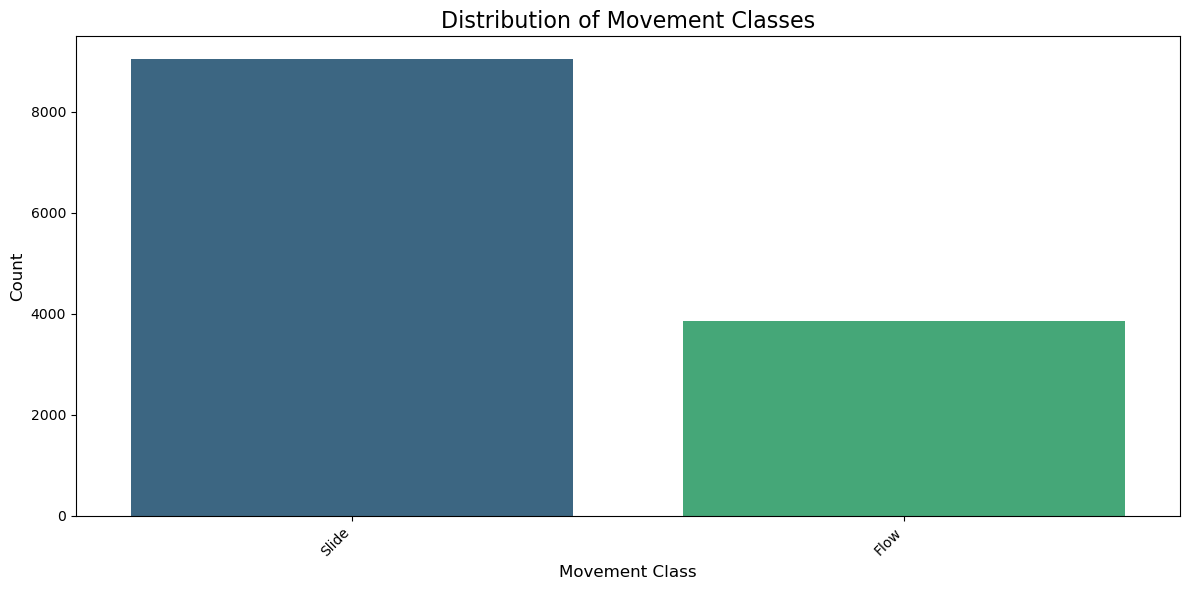
print("Movement distribution:")
print(gdf["filter_MOVEMENT"].value_counts().head(15))
Material distribution:
filter_MATERIAL
Complex 9042
Debris 2171
Earth 1696
Name: count, dtype: int64
Movement distribution:
filter_MOVEMENT
Slide 9042
Flow 3867
Name: count, dtype: int64
# Plot distribution excluding NaN values
plt.figure(figsize=(10, 6))
non_null_counts = gdf['filter_MATERIAL'].value_counts()
sns.barplot(x=non_null_counts.index, y=non_null_counts.values,
palette='viridis', hue=non_null_counts.index, legend=False)
plt.title('Distribution of Materials in Landslides', fontsize=16)
plt.xlabel('Material Type', fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
plt.figure(figsize=(12, 6))
non_null_counts = gdf['filter_MOVEMENT'].value_counts()
sns.barplot(x=non_null_counts.index, y=non_null_counts.values,
palette='viridis', hue=non_null_counts.index, legend=False)
plt.title('Distribution of Movement Classes', fontsize=16)
plt.xlabel('Movement Class', fontsize=12)
plt.ylabel('Count', fontsize=12)
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
gdf['filter_ORIGIN'] = 'CALIFORNIA_DC2'
gdf['filter_DATASET_LINK'] = 'https://maps.conservation.ca.gov/cgs/lsi/app/'
gdf['filter_REFERENCE'] = gdf['att_data_source']
Save into GeoJSON#
gdf.to_file("./processed_geojson/CAL_DC2_landslides_processed.geojson", driver='GeoJSON')
gdf.plot(figsize=(8, 6), edgecolor="k", linewidth=0.2)
plt.title("Cal Landslide Inventory")
plt.axis("off")
plt.show()
